
摘自 在 Hot Chips 22 上 GS464V 的演講
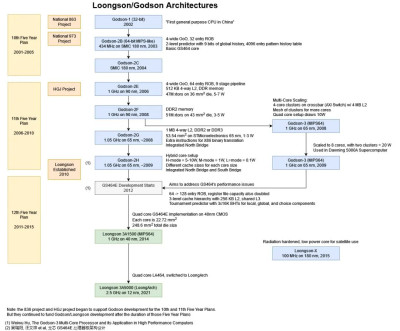
3A5000 的 LA464 內核從 MIPS 轉移到龍芯的內部架構,被稱爲 LoongISA 或 LoongArch。今天,龍芯希望 3A5000 能針對從個人電腦到服務器到嵌入式應用的所有領域。我們將深入了解該架構,看看它是如何努力實現這一承諾的。當然,我們也將把它與一些 AMD、ARM 和英特爾的架構進行比較。
我們的許多微觀基准測試都依賴於匯編代碼。編譯器往往會做一些不可預測的、復雜的事情,這使得我們很難從高水平的代碼中觀察到架構特性。不幸的是,這意味着我們不得不寫大量的代碼來研究龍芯的 3A5000。編寫匯編是很難的,而爲一個不熟悉的 ISA(LoongArch64)編寫匯編則將難度提高到另一個層次。測試微基准代碼也不容易。通常情況下,我們可以通過在具有已知特性的 CPU 上運行測試來驗證,並確保結果是理智的。但是龍芯的 3A5000 是我們唯一的 LoongArch64 CPU,而且大多數細節都沒有公开。出錯的幾率很高,所以在整個文章中要記住這一點。

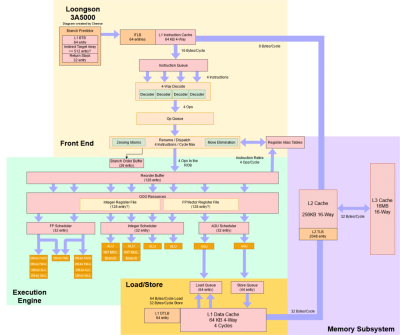
框圖
LA464 是一個4發射亂序結構,具有適度大小的緩衝器。在某些地方,它具有現代的功能,如物理寄存器文件和寬矢量執行。但這並不適用所有地方。總的來說,它是一個非常獨特的架構,具有我們在其他內核中沒有看到的設計決定。
前端:分支預測
一個 CPU 的流水线從分支預測器开始,它決定從哪裏獲取指令。分支預測器的性能對於實現高性能是絕對關鍵的。將流水线送入錯誤的路徑會造成工作的浪費,而花太長時間來確定一個獲取目標可能會使流水线餓死。3A5000 上的分支預測精度似乎相當不錯,能夠在 7-Zip 中與 Zen 1 和 Ampere Altra 抗衡。它在 libx264 中有點落後,但也不至於太差。
方向預測
GS464E 使用錦標賽式的預測器,其中元預測器選擇使用本地歷史或全局歷史進行預測。對於不熟悉的人來說,本地歷史指的是之前是否有分支,而全局歷史指的是指令流中之前的分支是否被佔用。本地歷史表、全局歷史表和選擇表在 GS464E 上都有 16384 個條目,與 DEC 的 Alpha 21264 中實現的經典錦標賽預測器相比,它顯得相當龐大。AMD 的推土機也使用錦標賽預測器,而 AMD 的優化指南暗示推土機微架構的全局歷史表也有 16384 個條目。
LA464 可能使用了一個類似的預測器。如果我們測試分支預測器在越來越長的隨機模式下的表現如何,龍芯的表現平平。它遠遠達不到目前英特爾和 AMD 的 CPU 的能力。最近的英特爾和 AMD CPU 使用了 TAGE(Tagged Geometric History Branch Predictor,標籤化幾何歷史分支預測器) 或感知器預測器,它們可以用更少的預測器存儲量達到更高的准確性。
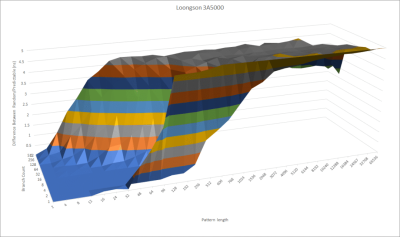
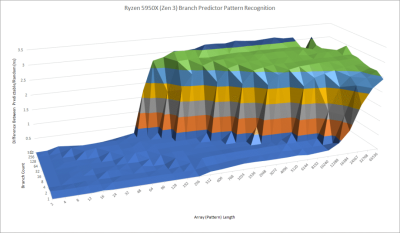
如果沒有相同口徑的分支預測,龍芯將很難在更大的核心下獲得良好的性能擴展。如果你不得不扔掉不正確的指令,那么更大的內核緩衝區來保持更多的工作,也不會有什么幫助。AMD 推土機微架構或龍芯的預測器可能足以滿足一個有 128 個 ROB 項的內核,但時代在進步,龍芯需要更好的東西來保持步伐。
分支預測器的速度
分支預測器的最終目標是加快分支處理速度。預測分支的去向當然很重要,但快速預測也同樣重要。如果你的分支預測器需要太長的時間來引導前端,你可能會導致管道中的指令被餓死。爲了加快速度,龍芯有一個 64 條 BTB(Branch Target Buffer 分支目標緩衝區,一個分支目標的緩存)。如果一個分支目標從這個 BTB 中出來,前端根本就不用停滯。
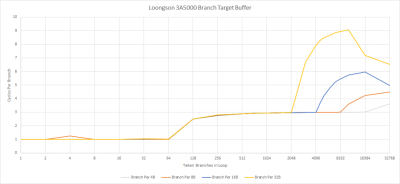
如果分支腳印從 64 個條目的 BTB 中溢出,CPU 必須等待分支從 L1i 中被取走,然後計算目標地址。在這一點上,所採取的分支延遲基本上是 L1i 延遲,這在 LA464 上似乎是三個周期。作爲比較,最近的英特爾和 AMD 的 CPU 即使在交出數千個分支時也只有一到兩個周期的延遲。這種延遲尤其令人痛苦,因爲 3A5000 的時鐘比 AMD 或英特爾的芯片低得多,所以實際時間的分支延遲相當高。
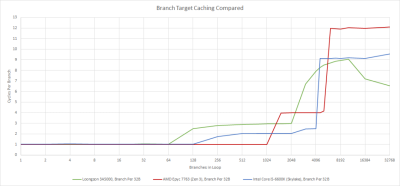
龍芯的方案避免了大型 L2 BTB 的面積成本,但阻止了分支預測器在 L1i 缺失後跟蹤指令流。英特爾、AMD 和 ARM 的 CPU 通過使用分支預測器從指令端驅動預取,可以在大代碼範圍內保持高指令量。雖然這種技術在 Sandy Bridge 和推土機時代是新技術,但今天它已成爲常識,甚至在低功耗架構上也能實現。在龍芯中沒有看到它,真像是從過去吹來的一陣風。
間接分支預測
通往多個目標的分支更難,因爲分支預測器也要在分支目標之間進行選擇。這些棘手的分支也被稱爲間接分支,因爲它們告訴 CPU 跳到寄存器中的一個地址,而不是直接編碼目標。對於一個間接分支,3A5000 在遇到懲罰(可能是錯誤預測)之前可以跟蹤大約 24 個目標。我們看到,在 256 個分支和每個分支兩個目標的情況下,總共跟蹤了約 512 個間接目標,而沒有受到明顯的懲罰。
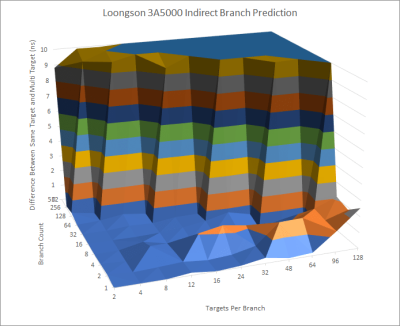
這種水平的間接分支處理能力是很好的。這也是相當值得贊賞的,因爲面向對象的編程語言傾向於使用間接分支來處理方法調用。但它的能力不如其他最近的CPU。
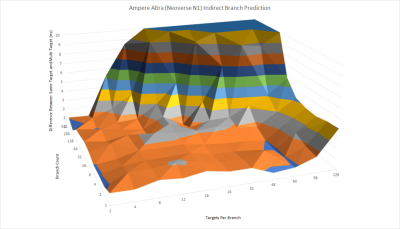
Neoverse N1 值得一提,因爲它也是一個具有適度性能目標的內核。但是 ARM 能夠實現間接分支預測的能力,與 Zen 3 和 Golden Cove 的能力相差無幾。龍芯則明顯落後。
返回預測
返回是間接分支的一種特殊情況,因爲它們通常出現在匹配的調用/返回對中。因此,許多 CPU 保留了一個返回地址的堆棧。在調用時,它們將一個地址推到堆棧上。爲了預測一個返回,他們從堆棧中彈出一個地址。龍芯爲 3A5000 提供了一個 32 個入口的返回堆棧,這對於絕大多數情況來說應該是足夠的。這比 GS464E 有明顯的改進,GS464E 有一個 16 條目的返回堆棧。
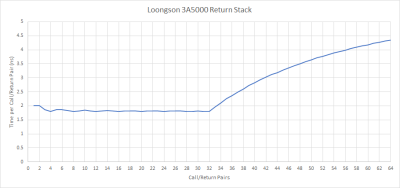
AMD 的 Zen 2 有一個類似大小的返回堆棧,並經常能夠實現超過 99% 的返回預測精度。
前端:指令獲取
一旦分支預測器確定了要去的地方,前端就必須把指令帶入內核。這就是指令側高速緩存層次的作用。首先,3A5000 有一個大的 64KB 4 路 L1i。這一點很好,特別是當 AMD 和 Intel 的高端 CPU 都採用較小的 32KB 指令緩存時。
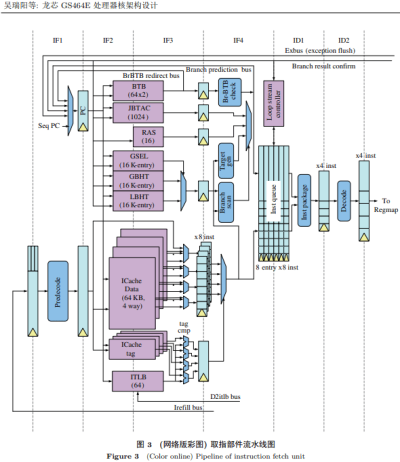
GS464E(前一代)的指令獲取管道。LA464 的獲取單元可能是類似的。
然而,看起來大的 L1i 是爲了緩解龍芯在從 L2 和其他地方獲取代碼時的不良性能。Zen 1 和 Skylake 在從 L2 提取指令時都能維持 4 的 IPC,即使他們不得不從 L3 運行代碼,仍然表現得非常好。龍芯無法與之相提並論,對於較大的代碼足跡來說,可能會被前端帶寬所限制。

奇怪的是,從 L2 獲取的代碼帶寬比從 L3 獲取的要差。我想知道龍芯在實現硬件指令高速緩存一致性時是否遇到了一些困難。如果做得正確,硬件指令緩存一致性可以使 JIT 化的代碼受益,並能更好地擴展到高核數。然而,這並不容易。龍芯的 L2 是非包容性的,這意味着它不能作爲一個窺探過濾器。也許一個來自指令端的 L2 命中必須探測 L1D,以確保它得到最新的數據。但是,L3 命中可能會受益於位於 L3 復合體中的單獨的一致性目錄,它可以指示是否可以在沒有窺探的情況下提供最新的數據。
重命名器
在指令被獲取和解碼後,重命名器必須在後端分配資源來跟蹤它們。除了顯而易見的寄存器重命名以打破虛假的寄存器名稱依賴之外,重命名器還可以使用某些技巧來向執行引擎暴露更多的並行性。最近的英特爾和 AMD CPU 可以做到這一點,在重命名器中自由處理寄存器到寄存器的移動和清零習慣。
據我所知,龍芯並沒有任何這樣的優化。重命名器做了你從計算機科學課程中所期望的事情,而這就是它。
亂序執行
吸收緩存和內存延遲是保持高性能的關鍵,龍芯有一個規模適中的亂序引擎來做到這一點。就規模和雄心而言,它看起來與 Neoverse N1 的隱約相仿。兩者都有一個 128 條目的 ROB,以及類似的寄存器文件大小。N1 有一個分布式調度器,而龍芯使用一個更統一的調度隊列配置,總條目更少。
結構適用於指令...龍芯 3A5000 (LA464)GS464E**Neoverse N1Zen 1重新排序的緩衝區存在128128128192整數寄存器文件寫入標量整數寄存器~91 speculative + 32 architectural = ~123 entry128120 entry180 entry矢量/浮點 寄存器文件寫入浮點/矢量寄存器~90 speculative + 32 architectural = ~122 entry
256-bit entries, ~3.9 KB total capacity128 entry
64-bit,
1 KB total capacity128 entry
128-bit entries, 2 KB total capacity160 entry
128-bit, 2.5 KB total capacity調度器正在等待執行32 entry INT
32 entry FP
32 entry memory16 entry INT
24 entry FP
32 entry memory16 entry branch
3×16 entry INT
2×16 entry FP
2×12 entry memory4×14 entry INT
36 entry FP + 64 entry NSQ
2×14 entry memory加載隊列從內存中讀出64 entry64 entry?56 entry116 entry*存儲隊列寫入存儲器44 entryShared with loads?44 entry44 entry分支順序緩衝區影響控制流26 entry24 entry36 entry136 Not Taken
32 Taken
*Zen 的優化手冊說負載隊列是 44 個條目,但核心可以保持 116 個負載在飛行。爲了保持一致性,使用了測量的 116 的數字
與較早的 GS464E 內核相比,LA464 保持了相同的重排緩衝區和寄存器文件大小,但龍芯加強了最重要的調度器大小。對於具有 128 個 ROB 項的 CPU 來說,GS464E 已經具有相當大的寄存器文件尺寸。LA464 應該能夠更好地利用其 128 條 ROB。但最近的 AMD、英特爾,甚至 ARM 的 CPU 都遠遠領先於龍芯。他們有更大的重排緩衝區,其他結構也得到增加,以保持核心的平衡。
龍芯可能選擇了保守的結構尺寸增加,以提高時鐘速度。如果要在通過加倍結構尺寸提高 IPC(就像 GS464E 對 GS464 所做的那樣)和通過提高時鐘速度提高整體性能之間進行選擇,後者肯定是更好的選擇。然而,西方公司在提高時鐘速度的同時也能增加結構尺寸,將龍芯甩在了後面。
整數執行
在前一篇文章中,我們介紹了矢量執行,所以如果你想了解 3A5000 上的 FPU,那么就去讀那篇文章。現在是時候看看龍芯 3A5000 的標量整數方面了。與 GS464E 相比,龍芯的 LA464 內核極大地提高了整數量,有四個 ALU 管道而不是兩個。之前的 GS464E 衍生的內核看起來總是有點滑稽,在一個 4 發射的內核裏有兩個 ALU。公平地說,每個推土機模塊中的內核都是4發射的,但只有兩個 ALU,但這是一個特殊情況,強調的是共享前端的多线程性能。
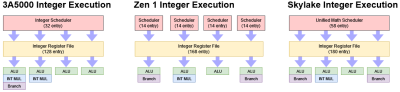
雖然龍芯在 GS464E 的基礎上進行了大規模的改進,但他們目前的內核在整數執行方面確實有一些不足之處。LA464 每個周期只能解決一個分支,即使該分支沒有被採納。這種能力相當於 ARM 的 Neoverse N1 或英特爾的 Sandy Bridge 能做到的。但是,較新的英特爾和 AMD CPU 可以在每個周期內維持兩個分支,通常提供至少一個分支沒有被採取。
指令 3A5000 Throughput/LatencyGS464E Throughput/LatencyNeoverse N1 Throughput/LatencyZen 1 Throughput/Latency64b Integer Adds4 per cycle
1 cycle latency2 per cycle3 per cycle
1 cycle latency4 per cycle
1 cycle latency64b Integer Multiplies2 per cycle
4 cycle latency2 per cycle
3 cycle latency1 per cycle
2 cycle latency1 per cycle
3 cycle latency64b Integer Divisions0.11 per cycle
9 cycle latency0.05 per cycle
20 cycle latency0.07 per cycle
8 cycle latency
注意,Neoverse N1並不支持256b指令。
龍芯在整數乘法的量方面確實有優勢。與 Gracemont 一樣,3A5000 可以在每個周期做兩次標量整數乘法,而其他大多數內核只能做一次。即使 3A5000 的時鐘速度很低,但在絕對量方面,它可以超過 2020 年前的 ARM 和 x86 對手。然而,與最新的 AMD 和英特爾台式機內核相比,這一優勢被削弱了,它們的時鐘是 3A5000 的兩倍多。它被整數乘法延遲進一步削弱,整數乘法延遲爲 4 個周期,表現平平。
矢量和浮點執行
我們之前研究了 3A5000 的矢量和浮點執行布局,沒有發現其能力弱於 Zen 1 和 Skylake。更多細節在那篇文章中。但總結起來,龍芯只有兩個矢量執行端口,並受到高 FP 執行延遲的影響。無論矢量寬度如何,浮點加法、乘法和融合乘法-加法指令的執行有五個周期的延遲。這與 AMD 的 RDNA 2 圖形架構的延遲相同,這很有趣,因爲 RDNA 2 也達到類似的時鐘。
矢量整數操作更好,矢量添加的延遲爲一個周期。盡管如此,一個四核 Ampere Altra 雲計算實例在 libx264 視頻編碼方面成功地超越了 3A5000,這要歸功於更高的時鐘速度和可能更廣泛的專門指令集的結合。就像標量整數方面一樣,3A5000 確實有優勢,能夠在每個周期進行兩次 256 位矢量整數乘法,使其與 Skylake 持平,並超過了 Zen 1。
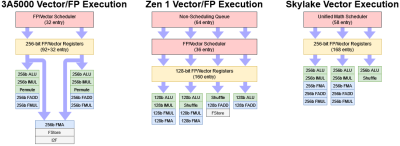
與英特爾和 AMD 的比較只是故事的一個方面。較早的 GS464E 核心有 64 位 FP 單元,使其回到了 x87 和 MMX 時代。龍芯當然要在他們得到的基礎上工作。當 ICT 管理狗剩(Godson)的开發時,他們創造了 GS464V,這是 GS464 的一個變種,具有強大的向量單元,用於超級計算機。我懷疑 GS464V 構成了 LA464 的矢量實現的基礎。根據 IEEE 的一篇論文,GS464V “在內核中集成了兩個256位的矢量單元”,並且“矢量ALU模塊被使用了兩次”。
地址生成
存儲器操作從地址生成單元开始執行,該單元計算出加載或存儲操作要尋址的存儲器地址,並將其傳遞給加載/存儲單元。龍芯 3A5000 的 LA464 內核有兩個AGU,使其在每個周期內執行兩個內存操作。兩個都可以是加載,一個可以是存儲。這使得它與 Neoverse N1、Zen 1 和 Sandy Bridge 大致相當。

然而,它比英特爾的 Haswell 架構及其後繼者落後一步,後者可以在同一周期內進行兩次加載和一次存儲。當前一代 AMD 和英特爾的 CPU 也有大規模擴展的內存執行能力。例如,Golden Cove 可以在每個周期進行兩次加載和兩次存儲。Zen 4 每個周期可以進行三次內存操作,其中兩次可以是存儲。當龍芯开發 GS464E 時,考慮到英特爾的 Ivy Bridge,雙 AGU 的設置似乎完全沒有問題。但時代在進步,現在看來已經相當過時了。
加載/存儲單元
一旦虛擬地址被生成,它們就會被傳遞給加載/存儲單元。加載/存儲單元確保內存依賴性得到尊重,並將虛擬地址轉換爲物理地址。爲了加快速度,龍芯可以推測地在未知地址的存儲之前執行負載。
如果一個負載確實從較早的存儲中獲取了數據,龍芯可以以 7 個周期的延遲轉發存儲數據。只要負載包含在存儲中,並且訪問不跨越 64B 緩存线的邊界,存儲轉發就能發揮作用。對於一個 2.5GHz 的 CPU 來說,7 個周期的存儲轉發延遲並不是最好的性能。Zen 1 有相同的存儲轉發延遲,但時鐘要高得多,而 Skylake 可以以 5 個周期的延遲轉發存儲數據(或者,只比無爭議的負載延遲多一個周期)。

龍芯的行爲有點像 Skylake,因爲兩者都做了一個粗略的檢查。龍芯以 8B 的粒度進行檢查,而 Skylake 則以 4B 的粒度進行檢查(即,比較一個額外的位)。這意味着,如果負載和存儲在龍芯上碰到同一個 8 字節的塊,即使它們沒有真正重疊,也不能平行進行。這個 8B 的重疊懲罰也適用於 16KB 的頁面。如果加載和存儲在不同的 16KB 頁面內的相同偏移量上觸及相同的 8B 塊,也會有一個錯誤的依賴性。最後,如果一個負載部分地與一個存儲重疊,龍芯會受到 14 個周期的懲罰。這種失敗的存儲轉發懲罰並不壞,而且與其他 CPU 的情況一致。
如果訪問跨越 64B 緩存线,負載/存儲單元的工作就會變得更難,因爲這將涉及到兩個 L1D 訪問。這種訪問被稱爲 "錯位訪問",因爲它們跨越了 L1D 對齊邊界。龍芯通過在兩個周期內執行錯誤對齊的負載來處理它們。這並不離譜,盡管較新的英特爾和 AMD CPU 根本沒有看到任何錯位負載的懲罰。存儲對龍芯來說要糟糕得多,因爲一個錯位的存儲需要 10 個周期。酷睿 2 時代的老英特爾 CPU 確實遭受了類似的懲罰,但最近的 CPU 通常要好得多。考慮到 CPU 的低時鐘,10 個周期的懲罰是相當可觀的。
如果一個訪問也跨越了 16K 頁的邊界,除了兩次 L1D 訪問外,還需要兩次 TLB 查找。龍芯對這種情況處理得很好,同樣的錯位加載懲罰,而錯位存儲懲罰增加到 15 個時鐘。Zen 1 需要 24 個周期的懲罰,如果 Zen 1 以 4GHz 的速度運行,實際時間幾乎相同。
地址轉換
在生成地址之後,內核必須將虛擬地址(如程序所見)轉換爲物理地址,與 DRAM 中的位置相對應。這種轉換允許操作系統執行權限,並爲每個進程提供自己的內存視圖,確保一個行爲不端的程序不會導致整個系統崩潰。然而,地址轉換也會產生开銷。TLB 通過記住這些地址轉換將這種开銷降到最低。
龍芯默認以 16KB 的塊,或頁來翻譯地址。作爲比較,X86 和 ARM CPU 通常使用 4KB 的頁。龍芯的大頁意味着每個 TLB 條目有更多的覆蓋範圍。LA464 有一個 64 個條目的 L1 DTLB,它可以覆蓋 1MB,由一個 2048 個 L2 TLB 支持,總 TLB 覆蓋範圍爲 32MB。這些大的頁面大小應該使龍芯比其 x86 和 ARM 的同類產品有一些優勢。
撞擊 L2 TLB 似乎比撞擊 L1 TLB 增加了 2.3ns 的延遲,或大約 5-6 個周期。這與 Zen 1 相比是有利的,後者的 L2 TLB 延遲爲 7-8 個周期。然而,Zen 1 的高時鐘意味着它享有更好的實際延遲。
緩存和內存訪問
一旦加載/存儲單元完成了它的檢查,它就會從內存層次結構中獲得所要求的數據。像許多現代的 CPU 一樣,龍芯使用了三層的緩存設置。今天所有的高性能 CPU 都依賴於緩存,因爲 DRAM 性能的提高並沒有跟上 CPU 核心性能的提高。
L1D 緩存
與以前的 GS464 系列的架構一樣,3A5000 享有一個大小適中的 64KB L1D。它是 4 路設置的關聯性,以實現虛擬索引,物理標記尋址的 16KB 頁面。然而,延遲是一個薄弱點。四個周期可能聽起來並不壞,但在 3A5000 的低時鐘速度下,我期待着更好的結果。AMD 的 K10 架構在使用舊工藝節點的更高時鐘下實現了 3 周期的延遲。
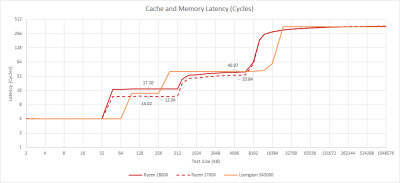
有效的 L1D 延遲變得更糟,因爲龍芯和 MIPS 一樣,缺乏一個按比例的索引尋址模式。編譯器最終產生了額外的指令來計算數組索引的地址,極大地增加了 L1D 的延遲。作爲比較,x86-64 和 aarch64 都有一個縮放索引尋址模式。最多,使用這種能力會產生一個周期的懲罰。在龍芯上,GCC 編譯的數組索引代碼的延遲爲 8 個周期,這在 2.5GHz 下是很殘酷的。
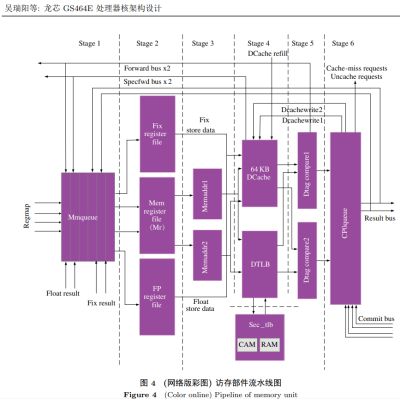
GS464E(LA464的前身)的 L1D 流水线
在帶寬方面,龍芯將 L1D 設置爲處理 256 位向量執行的需求。使用未記錄的 LASX 指令,我們能夠在每個周期內進行兩次 256 位的加載,或者一次 256 位的加載和一次 256 位的存儲。因此,3A5000 擁有比 Zen 1 更好的 L1D 帶寬,即使有 AMD 的時鐘速度優勢。然而,它無法與 Skylake 相比。
L2 緩存
像今天的許多 CPU 一樣,龍芯有一個 L2 中級緩存,使內核與 L3 延遲隔離。在 3A5000 上,L2 是 256KB,16 路設置關聯,並作爲一個受害者緩存。二級潛伏期一般爲 14 個周期。英特爾在過去的十年中一直以 12 個周期的延遲運行 256KB 的二級緩存,並且以更高的時鐘啓動。如果我們看一下實際的延遲,3A5000 的 5.6 納秒比 FX-8350 的 4.8 納秒還差。Zen 1 甚至比這更快,而且仍然有更多的 L2 容量。
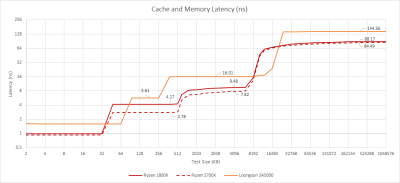
L2 帶寬平均爲每周期 21.3 字節——不是很好,也不可怕。這比 Skylake 每周期超過 28 字節,或 Zen 1 每周期超過 24 字節的情況要差一點。同樣,時鐘速度的差異意味着 AMD 和英特爾的舊 CPU 比龍芯的 3A5000 有明顯的實際二級帶寬優勢。
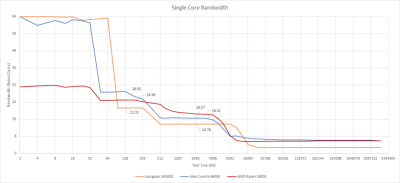
L3 緩存
龍芯的 L3 可以說是 CPU 最好的功能之一,因爲它爲四核集群提供了 16MB 的容量,具有不錯的帶寬和延時。L3 的功能是作爲一個受害者緩存,由四個庫構成。根據 3A5000 的用戶手冊,L3 和內核是通過一個使用 AXI 協議的“5×5分頻开關”連接的。CPU 內核作爲主站連接到开關,而 L3 緩存片作爲從站。开關端口的設置使每個端口每周期有 32 字節的讀取帶寬,每周期有 16 字節的寫入帶寬。
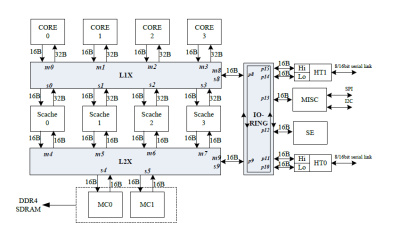
3A5000 的互連設置,如參考手冊上所述
這種互連設置可能是從 Godson 3 時代延續下來的,當時 ICT 致力於在高核數配置中實現舊的 GS464 內核。這並不令人驚訝,考慮到即使在轉到龍芯的所有權之後,同樣的人也在爲這個項目工作。然而,龍芯已經將每個 L3 片的讀取帶寬提高了一倍。
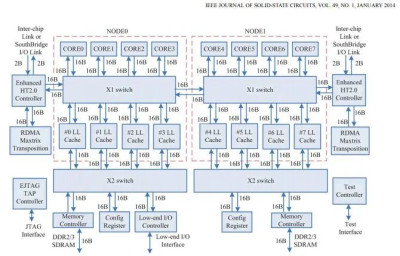
Godson-3B1500 的互連設置。在每個四核集群內,高層結構看起來非常相似。
有了四個 L3 片,每個片能夠在每個周期提供 32 個字節,我們應該在 2.5GHz 下獲得 320GB/s 的理論 L3 帶寬。我們沒有得到任何接近這個數字的東西。也許內核不能跟蹤足夠多的未完成的 L2 失誤來吸收 L3 延遲。也許在 5×5 交換器中存在爭論。也許 3A5000 對 L3 緩存的時鐘頻率低於核心頻率。畢竟,Godson-3B1500 以 1.25GHz 的頻率運行核心,但以 1GHz 的頻率運行 L3。
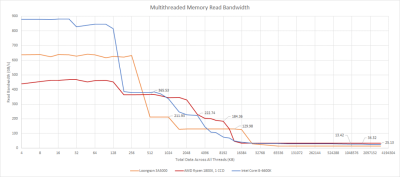
無論情況如何,AMD 和英特爾都有明顯的 L3 帶寬優勢。Zen 1 和 Skylake 都可以從 L3 每周期拉出更多的字節,而它們的高時鐘速度使龍芯更加落後。龍芯確實有容量上的優勢,但在面對 AMD 和英特爾的更多現代芯片時,這種優勢消失了。
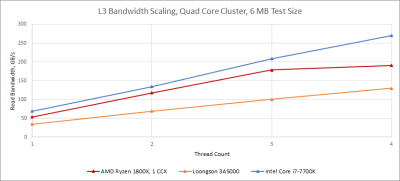
對龍芯有利的是,至少他們設法實現了一個遠比推土機架構好的 L3。我們看到,隨着线程數的增加,L3 帶寬的擴展大致是线性的。當龍芯的規模超過四核配置時,擴展性應該很好,因爲每個 L3 實例都是四核集群的私有資源。像 AMD 的 EPYC 一樣,L3 帶寬應該隨着更多核心集群的增加而线性擴展,除非有某種可怕的錯誤。
L3 有大約 40 個周期的加載—使用延遲。以周期計算,這還不錯,與 Zen 2 相似。然而,16ns 的絕對延遲對於一個客戶端設計來說是相當不引人注目的,對於一個運行在 2.5GHz 的 CPU 來說,龍芯確實應該有一個更短的 L3 管线長度。
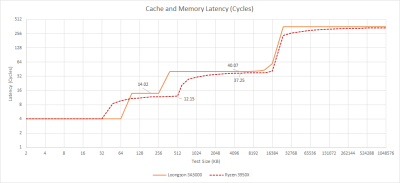
龍芯的 3A5000 與之前的 Godson-3B1500 相比確實很好。根據發表在 IEEE 上的一篇論文,Godson 3 的 L3 延遲約爲 50 個周期。在 1.25GHz 時,這將是 40 納秒。16 納秒是世界上最好的,所以龍芯公司取得的進步應該受到贊揚。
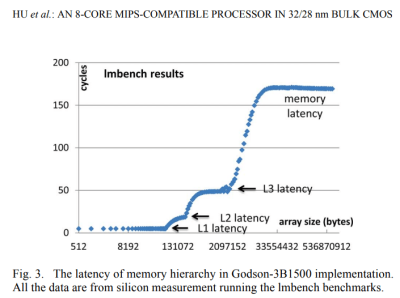
Godson-3B1500 在 1.25 GHz 核心和 1 GHz LLC 時鐘下的延遲結果,發表在《32/28 納米 Bulk CMOS 中的 8 核 MIPS 兼容處理器》,IEEE 2014 年
如果 3A5000 錯過了 L3,它通過第二級 AXI 开關訪問 DDR4 內存控制器。
DRAM 訪問
從上圖來看,Godson-3B1500 有 160-170個 周期的內存延遲,相當於 128-136 ns。對於使用 RDIMMs 的雙通道 DDR3-1066 配置來說,這還不算太糟糕。不幸的是,對於 3A5000 來說,龍芯在轉向 DDR4 時掉了鏈子。我們使用 DDR4-2666 測量了 144 ns 的內存延遲。龍芯一定是從 wish.com 購买的內存控制器,因爲它是一堆燃燒的垃圾。
我們用 DDR4-2666 進行測試,兩個插槽都裝滿了。3A5000 有一個雙通道內存控制器,這應該使它的理論帶寬與五到六年前的消費芯片相當。“理論上”是這裏的關鍵詞,因爲現實是不同的。
單個龍芯可以從 DRAM 中獲取約 7GB/s 的帶寬,而所有四個核心加起來也不過 14GB/s。在一個全核心的工作負載中,每個核心將不得不使用僅 3.37GB/s 的 DRAM 帶寬,這使得帶寬可能受到限制。對於雙通道 DDR4 設置來說,這是一個糟糕的性能,因爲它甚至遠遠落後於平庸的 DDR3 配置。例如,採用雙通道 DDR3-1333 的 i7-4770 的速度剛剛超過 19GB/s。
獲得便宜的內存控制器的後果會有所不同。像網頁瀏覽或文字處理這樣的日常任務可能沒有問題。服務器程序、HPC工作負載、圖像處理、視頻編輯和並行代碼編譯可能就不行了。
我們還應該記住,這是一個運行在 2.5GHz 的四核芯片。當龍芯試圖追求更高的時鐘速度或更高的核心數量時,內存性能將成爲一個越來越嚴重的問題,因爲計算與帶寬之比將變得更加糟糕。這在延遲方面也適用。144.5 ns 在 2.5 GHz 時是 361 個周期,但在 4 GHz時是 578 個周期。在某種程度上,3A5000 的非常低的時鐘速度掩蓋了其最糟糕的內存性能問題。
最後要說的是
龍芯的 3A5000 是我們迄今爲止看到的最有希望的中國國產 CPU。與飛騰 D2000 相比,龍芯的 3A5000 是一個寬核,具有更好的平衡後端和更好的緩存層次。但它在追求成爲通用 CPU 的過程中,遭遇了與其他兩款相同的基本問題。龍芯的 LA464 根本無法提供與任何近期英特爾或 AMD 架構相同的性能。與西方同類產品相比,LA464 的架構更小,L2 和 L3 緩存更差,DDR4 內存控制器也令人尷尬。即使龍芯把他們的核心從 1GHz 提高到 2.5GHz,也沒有人在這么低的時鐘下運行台式機甚至筆記本 CPU。由於其巨大的時鐘速度缺陷,龍芯甚至無法達到與最近的台式 CPU 相同的性能標准。它甚至在與運行在 3GHz 的 Neoverse N1 的對抗中掙扎。
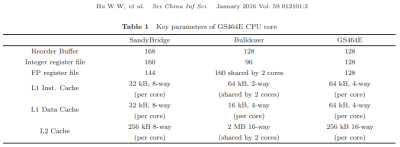
來自 “中國的 CPU 和 DSP 設計介紹”。所有列出的 GS464E“關鍵參數”在 LA464 上都是相同的。
龍芯的進展也不容樂觀。從微觀基准測試來看,LA464 的架構基本上比 GS464E——2010 年代初的核心——多出一代。GS464E 的設計是爲了在時鐘對時鐘的性能上接近於那個時候的西方核心。這是一個巨大的問題,因爲即使在那時,Sandy Bridge 和推土機微架構的時鐘也明顯高於今天的 LA464。當然,Golden Cove 和 Zen 4 也比 Sandy Bridge 領先很多很多代。
最後,龍芯/計算所團隊肯定一直在努力工作,試圖實現爲他們設定的目標。但是他們的創新速度落後於 AMD 和英特爾,這兩家公司一直在不懈地推動 CPU 性能的發展。但是看看 LA464,然後再看看 Zen 4 或 Golden Cove,就可以看到 AMD 和英特爾在推動 CPU 性能的邊界方面是多么令人印象深刻。它還顯示了西方公司的持續進步如何給中國的 CPU 制造商提供了一個非常困難的移動目標。
$上證指數(SH000001)$$龍芯中科(SH688047)$$芯片ETF龍頭(SZ159801)$
本文作者可以追加內容哦 !
鄭重聲明:本文版權歸原作者所有,轉載文章僅為傳播信息之目的,不構成任何投資建議,如有侵權行為,請第一時間聯絡我們修改或刪除,多謝。
標題:龍芯的3A5000解析
地址:https://www.twetclubs.com/post/12869.html