“未來可能不是百模大战,而是萬模群舞。”自ChatGPT掀起大模型的發展熱潮之後,層出不窮的大模型已然蜂擁而入,風雷激蕩。但在經歷了最初的驚豔之後,行業已轉移到對商業化落地的冷靜觀察,一方面業界認可垂直類應用模型有望率先實現落地應用,另一方面AI大模型的壓縮和優化發展,使得向邊緣端滲透的步伐也在加快,邊緣算力的重要性正加速凸顯。
以更直觀的數據來看,有預測到2030年,邊緣計算潛在市場將在10年內以48%的復合年增長率從2020年的90億美元增長到2030年的4450億美元。而且,中國是邊緣算力的主战場,預估到2026年全球26%的網絡邊緣站點將位於中國。
通用GPU這一算力主流芯片在經過AI的淬煉之後,如何更進一步,承接AI大模型下沉至邊緣端的新機遇?無疑,這將更是一場實打實的硬仗。
可重構架構打造算力第三極
在日前舉辦的第六屆世界人工智能大會(WAIC)上,珠海芯動力、天數智芯、燧原科技、登臨科技、愛芯元智、沐曦等企業展出的芯片、加速卡、軟硬件解決方案和廣泛的行業應用,成爲WAIC不容錯過的“風景”。

在WAIC舞台同場競技的背後,暗藏的邏輯是通用GPU廠商比拼的賽點,已經從單純的性能指標轉向進入真實應用場景落地的較量,邊緣側的競奪也走向白熱化。
“隨着AIGC興起,算力將成爲重要的生產力。相比雲端,邊緣側應用場景更廣泛,也更能促進生產力的提升創造價值,將對通用GPU產生巨大的市場機會。”芯動力CEO李原樂觀表示。
顯然這涉及通用GPU的算力、擴展性和編程性、生態等多維度的比拼。在這一市場,英偉達、AMD、英特爾等佔據強勢地位,且在當下國內半導體制造面臨全面打壓的情形下,我國通用GPU企業想要撕开一道口子,有專家建議不能按“常理”出牌,需要從架構、材料、封裝等層面進行創新。
不走尋常路,發布首款基於可重構架構的GPGPU芯片RPP-R8的珠海芯動力可謂獨闢蹊徑。該公司在2017年成功研發出可重構並行處理器(RPP)架構,借助於獨有的底層硬件架構,自帶高性能、原生支持CUDA語言和低功耗等“光芒”,可對AI推理的性能進行深度優化。

(RPP-六邊形战士)
芯動力創始人李原分析,在可重構芯片面世之前,AI算力芯片主要有專用和通用GPU兩大類,專用芯片性能雖強但編程能力差,有的通用GPU可編程性高但算力不強,要從激烈的競爭中脫穎而出,必須建立強大的優勢,而第三類可重構芯片則將兩類產品的優勢“合二爲一”,將躋身成爲通用GPU的新一極。
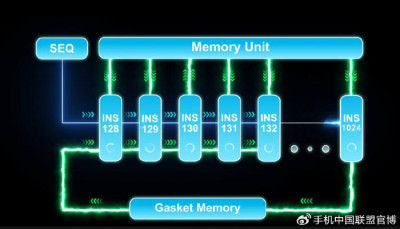
據悉,RPP-R8作爲一款通用GPU,每顆芯片內含有1024個計算核,相比傳統GPU架構在同樣的算力佔用更小的芯片面積,實現了低功耗和高能效的有效平衡。此外,面積效率比可達到同類產品的7~10倍,能效比也超過3倍。而且,除原生支持CUDA之外,芯動力還擁有自主开發的工具鏈,使得其能夠在cuDNN和TensorRT上實現API的兼容,同時也支持廣泛的人工智能框架,如TensorFlow和Pytorch等,可全面滿足高效並行計算及AI算力應用。
憑借高能效、高算力、低功耗、編程靈活等功力的“加持”,芯動力的RPP-R8在邊緣側的落地也在快馬加鞭。
解決客戶痛點 打开落地之旅
觸及落地,盡管RPP-R8的性能和生態獨樹一幟,但作爲一個新生“物種”,仍要面臨逐級解鎖的過程。
對此李原認爲,邊緣側的市場巨大,傳統市場的AI加速是剛需,通用GPU可替代專用芯片打入供應鏈;而新興市場的需求如智能安防、機器視覺等市場也在持續擴容。但落地最重要的是要解決客戶的痛點,要釐清市場的規律。
李原進一步剖析,芯片公司容易陷入提倡軟硬件一體化的“怪圈”,但邊緣側終端客戶對成本並非那么敏感,從產業鏈來看,芯片公司的客戶大都爲設備廠商,處於終端客戶的下遊,一方面芯片公司要學會將更多利潤留給設備廠商,讓他們有動力合作切入市場,另一方面芯片公司的客戶大都有實力進行軟件自主开發,因而要順應軟硬件分離的需求。

“因而,芯動力提供的是一個過硬的純硬件,加上底層兼容x86、Arm、Windows等軟件系統,與其他家的軟件結合在一起可快速應用,讓客戶可順暢地進行开發,有效幫助企業降低开發成本和產品周期,加速產品迭代與擴展,這是共贏之道和長久之道。”李原分析說。
基於這樣的深刻洞察,加上直擊痛點以及秉承讓利的“哲學”,讓芯動力的產品在落地之旅行進在“坦途”之上。李原提到,芯動力產品在智能安防、工業自動化等一些行業因可切實解決設備廠商的痛點,具有不可替代性,起量非常快,基本已處於拐點,更大規模的出貨將順利推進。
而這只是芯動力的“一小步”,未來還有更遼闊的徵程。
李原介紹,芯動力已推出了基於可重構架構RPP-R8系列三種不同封裝形式的GPGPU芯片,分別是AE8100、AE7100和AE6100;每一款芯片能夠滿足相對的應用場景需求。

“AE8100芯片面向邊緣服務器等領域,對體積、功耗要求較高;AE7100芯片着力面向低功耗、小體積的應用場景;AE6100則聚焦於更小體積上承載更大的性能,正在與客戶一起定義,針對機器視覺的Camera,融合信號採集、圖像處理和GPU加速等功能,以代替前端的ISP,下半年將着重在工業視覺領域實現新的突破。”李原躊躇滿志表示。
不再跟隨?創新當道
在AIGC熱潮掀起通用GPU的算力革命之際,一個更值得業界深思的問題也浮出水面。
“業界均認爲AIGC大模型是一大風口,一大史詩級機遇。但值得深思的是,中國這么多AI公司和GPU公司,爲什么美國开大模型之先河?如果不深刻反省,下次再有風口出現時我們還是被動跟隨的境況。”李原的表述中藏着一些深層的內省。
李原進一步提議,對國內高科技界來說,最重要的是要思考未來十年會向什么方向演變?如果只是一味地跟隨或Repeating,實際上沒有太大價值,也走不出這一循環。
着眼於通用GPU發展,李原高瞻遠矚地表示,下一個十年比拼的是它的效率,而不僅是性能。爲持續降低時延和提高帶寬,將衍生出衆多新技術,業界應着力解決芯片外部互聯挑战,並嘗試採用光電子技術,突破原有的方式才有可能實現超越。
此外,chiplet成爲未來算力芯片“擴張”的必然之路,也將產生更多Cost Effective的效果。李原提到,芯動力也將在這一方向持續耕耘,加強與FPGA廠商合作共贏,切入更多場景,爲客戶帶來更具想象力的價值。
對於CUDA兼容的走向,李原也洞察道,客戶不在意底層是用CUDA或別的語言,最重要的是能夠快速迭代、快速开發。在已經選用了CUDA語言的領域裏,我們會尊重客戶的選擇,但在新的領域裏,完全可以有自由的選擇。
伴隨生成式AI帶動下的這場新興科技革命,邊緣計算的價值將被如芯動力這批“搶灘登陸”的企業率先釋放,而芯動力的未來之路,也將成爲國內衆多行業的數字化、智能化轉型升級的動力之源。
(來源/愛集微)
本文作者可以追加內容哦 !
鄭重聲明:本文版權歸原作者所有,轉載文章僅為傳播信息之目的,不構成任何投資建議,如有侵權行為,請第一時間聯絡我們修改或刪除,多謝。
標題:大算力時代 芯動力走出可重構架構創新“芯”路徑
地址:https://www.twetclubs.com/post/14336.html