作者|錢德新
今年2月,哈佛醫學院教授Tiffany H. Kung給ChatGPT出了一套美國醫學執照考試。
得出的結論是,ChatGPT在三個專家級知識的標准化測試中能夠達到或接近60%的准確度,其輔助診斷的表現已經接近醫生。
另一教授Ateev Mehrotr也對ChatGPT進行了測試。
結果顯示,ChatGPT在45個案例中的39個診斷正確,正確率87%(超過了現有機器診斷率的51%),並爲30個案例提供了適當的分診建議。
而ChatGPT在醫療領域的應用,在GPT-4發布後再次成爲焦點。
據OpenAI的內部評估,GPT-4在產生事實回復時其性能比GPT-3.5好40%,在參加爲人類設計的考試中表現比之前版本更好(例如醫學知識自我評估計劃(75%vs 53%))。以及,多模態輸入也讓GPT4能夠直接轉錄手寫紙質處方。
甚至,未來有一天給你开診斷書的可能不是醫生,而是AI。
01
硅谷巨頭們都在做什么?
谷歌可能是極少數意識到GPT對醫療領域重要程度的巨頭之一。
在ChatGPT發布後僅幾周,谷歌就公布了Med-PaLM,一個在更窄的參數範圍內運行的,專門用於回答醫療保健相關問題的大型醫用語言模型。3個月後,谷歌就馬不停蹄的公布了Med-PaLM 2。
但微軟想要更快。
Med-PaLM 2發布幾天後,Nuance(被微軟2021年收購)發布了一款讓醫生臨牀記錄“iPhone化”的殺手級AI應用,也是醫療行業第一款結合GPT-4模型的應用。
巨頭緊鑼密鼓地在醫療領域落地GPT,很大程度源自醫療是一個高度垂直的行業。
有券商曾在今年2月的一份研報中,詳細列出了以ChatGPT爲代表的AI技術的四條應用推演路线,其中除了獨立工具、深度嵌入生產力工具和與服務型應用結合,還有一條就是垂直領域。
由於醫療領域的專業性和特殊性,其對語言模型的質量要求遠高於市面上任何一種通用語言模型。所以,雖然比爆火的ChatGPT來得晚了一些,但生成式AI在醫療上有着充分的發揮空間。
而這場馬拉松比拼的不是誰先起跑,而是怎么跑。
知乎上曾有答主將ChatGPT與醫療從業人員的學習路徑做了一個比較,如果單從時間跨度來看,一個基於GPT-3.5模型的醫療大模型,可能在幾天或者幾周內即可完成培訓,而一個專科專家即便按照最短耗時計算,也要20年。
這相當於論證了GPT應用到醫療領域的廣闊前景。
具體來說,復旦大學附屬華山醫院信息中心主任黃虹就曾表示,醫療GPT重要的應用場景可以是就醫導診、醫院內部知識庫的構建和輔助醫生提升電子病歷的書寫效率。
醫聯創始人、CEO王仕銳先生近日也公开表示,AI醫生與互聯網醫院的結合,將爲醫療領域帶來前所未有的化學反應。
02
巨頭們忙於訓練AI醫療大模型的目的
券商對於AI技術落地垂直領域的推演,其中值得關注的一點在於,垂直領域大模型與通識大模型是不相同的。
在涉及專業知識的領域,ChatGPT爲代表的大語言模型通過與搜索引擎結合能對專業信息進行匯總、檢索,並附上來源,但模型本身在專業領域尚無法提供精准的回答,也無法運用專業知識解決綜合性的專業問題。
不過,大模型最重要的一個步驟在於,需要用專業的數據投喂、訓練、迭代,才能越來越契合垂直領域。Med-PaLM 2在被訓練近3個月後,表現提高了18%就能說明一些問題。
未來隨着更多的專業Know-how注入,以ChatGPT爲代表的AI技術有望在需要較強專業知識的垂直領域得到進一步的應用。
中科院院士、中山醫院心內科主任葛均波就明確表示過,AI臨牀應用結合大數據,將會極大延伸醫療服務“上下遊”,實現全生命周期管理。“AI助力將可爲患者從預防、發病、診斷、治療到院外康復的疾病管理全流程提供智能解決方案。”
事實上,忙於訓練AI醫療大模型的硅谷巨頭,已經在开發上述其中一個環節的落地產品了。
比如在最簡單的臨牀記錄生成層面,依靠GPT-4強大的生成式大語言模型和推理能力,DAX Express將這個過程從4個小時縮短到僅僅幾秒鐘。
英偉達則通過NVIDIA AI Foudations雲服務,以幫助需要構建、完善和運行自定義大型語言模型及生成式AI的客戶加速生成式AI的引入。這一服務包括用於自然語言處理的Nemo、圖像處理的Picasso,以及針對制藥業的BioNeMo。
AMD在收購賽靈思後,後者的FPGA芯片也在規劃在輔助病情診斷(慢性病篩查和風險評估)等場景,通過學習過往慢性病患者數據可以預測未來患病風險。這類場景使用FPGA也可實現模型訓練、推理性能的提升。
當然,國內也有相關公司意識到醫療GPT的價值。4月28日,醫聯就對外公布了國內首款大語言模型驅動的AI醫生——MedGPT,該產品目前已進入內部測試階段,並計劃於5月份正式發布。
03
醫療GPT,要腳踏實地
硅谷巨頭的技術和產品,雖然按照過往的邏輯可能會很快傳到大洋彼岸,但今天往後也可能不會。
由於衆所周知的原因,AI本身就是一個被限制的技術。更重要的是,大模型的本質是通過概率最大化不斷生成數據,而不是完全通過邏輯推理對問題進行解答的算法模型。
換言之,對一個大模型來說,數據和技術同樣重要。其中數據的大小、提煉程度,又決定了大模型的能力。美國的醫療數據不一定適合中國人,地理位置、氣候、飲食習慣等等諸多的不同,導致問題也會不同。
並且,若是基於邏輯推理對問題進行解答的邏輯,目前搜索引擎出現的問題,也仍將存在。今年ChatGPT針對算法錯誤修復的版本更新,便明確了這一問題的存在。如果直接把這項技術丟進互聯網醫院進行應用,後果可想而知。
所以要考慮GPT技術在醫療場景的應用,就要跳脫出固有思維。
首先,一定要有專門的數據喂養。更多專業Know-how的注入,以及專家進行語料標注,不斷清洗數據,才能提高模型的准確度。
以醫聯的MedGPT爲例,醫聯作爲一家互聯網醫院,其本質就是醫患關系鏈,以及在關系鏈上發生的醫療決策、服務和商品。這意味着,基於醫聯超過150萬的注冊醫生和2000萬患者深度互動而沉澱出來的專業數據,足夠投喂一個醫療大模型。
同時,醫聯專業的疾病全流程管理能力,針對各個疾病病種研發的專業SOP,以及智能化的患者疾病管理功能,也爲沉澱數據,最終訓練出這樣的醫療大模型提供了重要的醫療底層能力基礎。
其次,只有從業者才能做得更好,也就是需要最好的技術+最好的醫療能力。
醫聯自研的MedGPT採用了大模型技術,基於醫療知識圖譜爲模型提供豐富、准確、結構化的醫療知識、並收集整理接近20億條真實醫患溝通對話、檢驗檢測和病例信息進行深度訓練學習,同時利用醫生真實反饋進行強化學習,用以保障模型的推理質量、准確性與可靠性。值得一提的是,醫聯MedGPT首次突破了AI醫生無法與真實患者連續自由對話的難點,並實現了醫療問診場景中支持多模態的輸入和輸出。
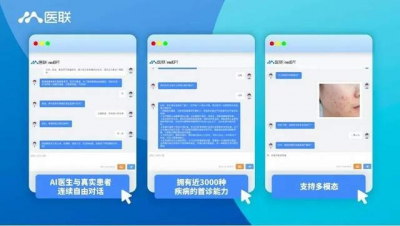
據了解,目前醫聯MedGPT擁有近3000種疾病的首診能力,覆蓋80%以上的成年人疾病種類和90%以上的0-12歲兒科疾病。
第三,與傳統的醫療服務相比,GPT的優勢更明顯。
還是以MedGPT爲例,在互聯網醫療的土壤中,它實際上具有高效便捷、精准預測、個性化服務和數據共享等多種特徵。
通過使用醫聯MedGPT,患者可以更加快捷、准確地解決與提供自身問題,這無疑爲患者提供了更加個性化、專業化的診療服務。
更重要的是,MedGPT基於大量問診數據訓練,能夠將患者從就診問診到疾病識別再到後續的治療建議環節進行智能且科學的串聯,也就是在疾病的預防、診斷、治療、康復四個重要環節全面實現智能化。
值得一提的是,基於嚴肅醫療理念,爲了檢驗MedGPT的科學性,醫聯抽取了平台532名復診患者進行實驗。結果顯示,醫聯MedGPT的診斷結果與原有診斷吻合率超過97.5%,充分證明了AI醫生在醫療領域的價值和潛力。
04
前景廣闊 值得期待
斯坦福大學醫學院教授Robert Pearl最近的一個觀點比較有代表性,他認爲AI對醫生來說將比過去的聽診器更重要,任何醫生都不該把ChatGPT或其他形式的生成式AI拒之門外。
Pearl認爲,ChatGPT可以幫助醫生來撰寫患者的臨牀報告、診斷書,甚至在和患者交流遇到困難時向醫生提供建議。生成式AI語言模型可以挖掘數字診療檔案中的有用信息,也能爲患者提供簡潔明了的專業解釋。
但實際上AI+醫療還不止如此。甚至,對於整個互聯網醫療模式都將產生積極影響。
譬如醫聯平台上現有的线上復診隨診、送藥上門、指標監測、用藥指導、不良反應幹預、醫保支付、健康科普等服務,在引入MedGPT後不僅整個流程會有一個效率上的提升,更能推動上述各個領域的服務專業度、服務質量更上一層樓。
事實上,醫療GPT更大的應用場景還是在基層。
一方面因爲基層醫療資源匱乏而導致醫患供需失衡,如果引入類似MedGPT的醫療GPT,那么對於基礎疾病的識別判斷,可以幫助患者更有針對性地選擇適宜的治療方式及治療路徑;
另一方面,高效准確的普篩,可以減少優質醫療資源擠兌,提升基層醫療環境的疾病診斷能力,爲分級診療制度的實施賦能。
據了解,醫聯也將在5月釋放大模型能力,屆時我們將能看到更多AI與互聯網醫院的能力結合以及更多的應用空間展示。$硅谷天堂(SZ833044)$
本文作者可以追加內容哦 !
鄭重聲明:本文版權歸原作者所有,轉載文章僅為傳播信息之目的,不構成任何投資建議,如有侵權行為,請第一時間聯絡我們修改或刪除,多謝。
標題:醫療GPT,硅谷又跑在了前面?
地址:https://www.twetclubs.com/post/4591.html